Evaluators
As an evaluator, you're often faced with complex programs operating in challenging contexts. Causal Map offers a powerful tool to make sense of qualitative data and stakeholder narratives, helping you uncover the real impact of interventions.
Why Causal Map?
- Answer research questions, such as ‘What are the main impact pathways of the intervention?’, ‘Are there unexpected outcomes?’, ‘Do your grantees see the world the same way as you do?’
- Present findings in clear, intuitive visual formats
- Facilitate participatory analysis and learning processes
- Test and refine theories of change based on stakeholder experiences
- Analyse large amounts of qualitative data efficiently
- Visualise complex causal pathways from program activities to outcomes
Case Study: Does our theory match your theory? Theories of change and causal maps in Ghana
This case study evaluated an entrepreneurship programme for rural women smallholders in Ghana, supported by Opportunity International UK.
The evaluation used the Qualitative Impact Protocol (QuIP) to gather participant stories and compared their perceptions of change with the programme’s original Theory of Change, using the Causal Map app to create causa maps to visualise the data and answer evaluation questions, revealing insights into the alignment between participant experiences and organisational theories:
- What do the intended beneficiaries think about the drivers of change in their livelihoods and lives?
- Do their perceptions match up with the theories of change constructed by organizations trying to support them?
- Is the programme Theory of Change well adapted to the realities on the ground from the perspectives of key stakeholders?
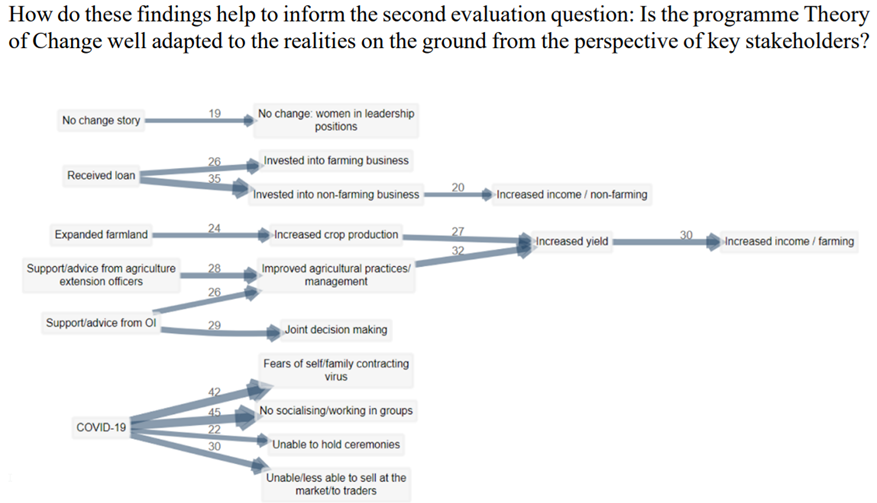
Case Study: AgDevCo, Uganda
This case study showcases how Causal Map was used to analyse the impact of AgDevCo's investments in Ugandan agribusinesses. The app helped synthesise data from 48 interviews and 8 focus groups with farmers, workers, and other stakeholders to answer research questions such as ‘What are the impact pathways caused by the investments on local communities and economies and how do they relate with changes in the complex system?’
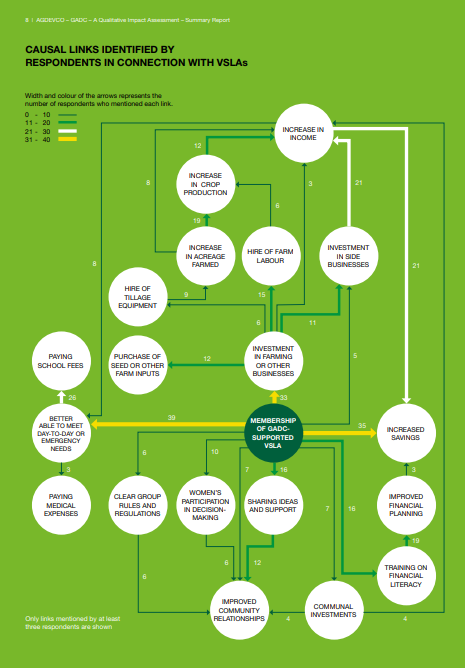
Source: AGDEVCO – GADC – A Qualitative Impact Assessment – Summary Report, p.8
Check our subscription options if you’re interested in using the app yourself or our consultancy packages if you prefer that we do the work for you!